Text Analytics: Analyzing Text Data to Extract Meaning and Insights

Text analytics is analyzing text data to extract insights and meaning from it. The growing availability of textual data from many sources, including social media, consumer reviews, emails, and polls, has made text analytics a crucial component of data and business analytics.
Text analytics in data science involves using statistical and machine learning techniques to extract insights from unstructured text data.
Understanding Text Data
Text data can come in different forms, including social media posts, customer reviews, emails, support tickets, surveys, etc. This makes it challenging to extract meaningful insights from text data.
Text mining involves preprocessing, transforming, and analyzing unstructured text data to discover patterns, trends, and insights.
Understanding the different types of text analytics and the pre-processing procedures necessary to make it suitable for text analytics is crucial for overcoming this challenge. The various text data types include:
- Short Text: This includes tweets, comments, and chat messages, which are typically shorter than 140 characters.
- Long Text: This includes articles, reports, and essays, which are typically longer than 140 characters.
- Semi-structured Text: This includes emails, support tickets, and product reviews, which have a basic structure but also contain unstructured information.
- Multilingual Text: This includes text data in different languages and requires specialized techniques for analysis.
To make text data usable for analysis, pre-processing steps are required, including:
- Text cleaning: Involves removing irrelevant information such as stop words, punctuation, and special characters.
- Text normalization: This involves converting text to a standard format, including converting all text to lowercase, stemming, and lemmatization.
- Text tokenization: This involves breaking down the text into smaller parts, such as words or phrases.
- Text encoding: This involves converting text into numerical representations that machine learning algorithms can process.
Businesses can gain valuable insights from their text data by understanding the different types of text analytics and the pre-processing steps required to make it usable for analysis.
Text Analytics Techniques
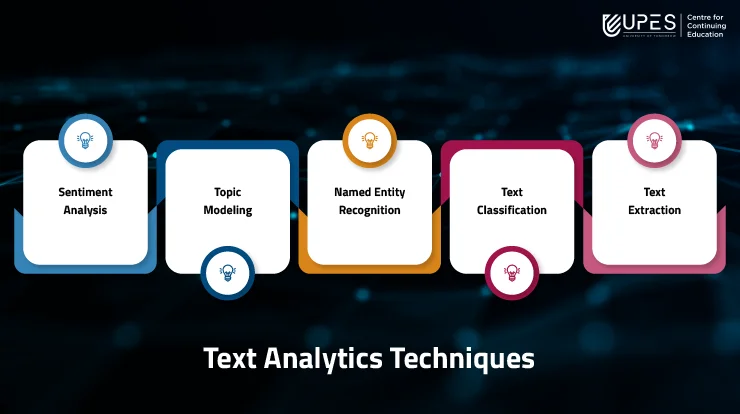
Text analytics involves using different techniques to extract insights and meaning from text data.
Text mining techniques like association rule mining, clustering, and text classification can help businesses extract valuable insights from large volumes of unstructured text data.
A. Sentiment Analysis:
Whether a text is favorable, harmful, or neutral requires assessing its sentiment. Sentiment analysis can monitor brand reputation, discover new trends, and comprehend client attitudes and responses to goods or services.
B. Topic Modeling:
This involves identifying the topics discussed in a collection of documents. Topic modeling can be used to discover themes in customer feedback, social media conversations, and other text data.
C. Named Entity Recognition:
This involves identifying named entities such as people, places, and organizations mentioned in text data. Named entity recognition can extract information from news articles, social media posts, and other text data.
Text analysis examples include sentiment analysis of social media posts and topic modeling of customer reviews.
D. Text Classification:
This involves categorizing text into predefined categories based on the content of the text. Text classification can classify customer feedback into different categories, such as product quality, customer service, and delivery.
E. Text Extraction:
Specifically, this entails retrieving dates, addresses, or phone numbers from text data. Emails, trouble tickets, and other text data can all have information extracted from them using text extraction.
Popular text analysis tools include NLTK, spaCy, and TextBlob, which offer various functionalities such as tokenization, part-of-speech tagging, and sentiment analysis.
Extracting Insights from Text Data
Extracting insights from text data requires a structured approach that involves several steps.
By following this structured approach, businesses can use text mining to unlock the value of their unstructured text data and make data-driven decisions.
A. Define the problem:
The first step is to define the problem or question you want to answer with text analytics. This could be understanding customer sentiment, identifying emerging trends, or detecting fraud.
B. Collect the data:
The following stage is to gather pertinent text data from various sources, including social media, client reviews, and polls. Once more, it is crucial to ensure the data gathered accurately reflects the issue being resolved.
C. Preprocess the data:
As discussed earlier, the third step is to preprocess the data by cleaning, normalizing, tokenizing, and encoding. To guarantee that the data is in a format that can be studied, preprocessing is crucial.
D. Apply text analytics techniques:
The fourth step is applying appropriate text analytics techniques, such as sentiment analysis, topic modeling, named entity recognition, text classification, or text extraction, to the preprocessed data.
Text analysis in big data requires scalable and distributed computing frameworks like Hadoop and Spark to process and analyze large volumes of text data.
E. Interpret the results:
The final step is to interpret the results and extract insights. This involves understanding the output of the text analytics techniques and mapping it back to the original problem being solved.
Analyzing Text Analytics
Natural language processing (NLP) includes text analytics, which is advancing quickly because of developments in machine learning and artificial intelligence (AI). Therefore, staying current with the newest text analytics methods and technologies is crucial to maximizing text data’s value.
Markets and Markets predicts a 30.2% CAGR for the worldwide text analytics market, increasing from USD 3.2 billion in 2020 to USD 11.9 billion by 2025.

Here are some factors to consider when analyzing text analytics:
A. Accuracy:
The accuracy of text analytics techniques is crucial to ensure that the insights extracted are reliable. Businesses should evaluate the accuracy of different text analytics tools and techniques before selecting them for analysis.
B. Scalability:
Text data can be vast, and using tools and techniques to handle large data volumes is essential. Therefore, businesses should consider the scalability of text analytics tools before selecting them for their analysis.
C. Integration:
Text analytics tools should integrate seamlessly with existing business processes and technologies. Businesses should consider the ease of integration when selecting text analytics tools.
D. Interpretable Results:
The results of text analytics techniques should be interpretable to ensure that the insights extracted are actionable. Businesses should select tools and techniques that produce interpretable results.
E. Ethical Considerations:
Text analytics raises ethical considerations such as privacy concerns and bias in the analysis. Businesses should consider the ethical implications of text analytics and take steps to address any potential issues.
By considering these factors, businesses can select the right text analytics tools and techniques and use them effectively to gain insights from their text data.
Relationship between Text Analytics and NLP
Natural language processing (NLP), which uses computational methods to analyze and comprehend natural language data, is a subfield that includes text analytics.
Text analytics NLP techniques such as tokenization, part-of-speech tagging, and syntactic parsing to preprocess text data before applying text analytics techniques such as sentiment analysis, topic modeling, and named entity recognition.
A significant difference between text mining and text analytics is that text mining focuses on discovering patterns and insights from large amounts of unstructured text data. NLP techniques can also improve the accuracy of text analytics.
A part-of-speech tagger, for example, can help improve sentiment analysis by identifying negation, sarcasm, and other linguistic features that affect sentiment.
Text analytics Python can be performed using libraries such as NLTK, spaCy, and TextBlob, which offer various functionalities for preprocessing, analyzing, and visualizing text data.
Conclusion
Data-driven decisions are made through text analytics, an essential business tool. Businesses must use a structured approach to interpret text analytics tools and techniques, considering accuracy, scalability, integration, interpretability, and ethical considerations.
UPES Online Admission Enquiry
Recommended Courses




Latest Blogs

Online MBA Exam Patterns: What to Expect & How to Prepare
Know the online MBA exam pattern in India. Assessment weightage, proctored exams, security & practical preparation strategies for online learners.
Read MoreJan 20, 2026 I 7 mins
General MBA vs Specialized MBA: How to Choose Your Path in 2026?
General MBA vs specialized MBA compared on metrics like scope, ROI, salary & career growth in India. Understand the path & choose wisely.
Read MoreMay 3, 2026 I 8 mins
Product Analyst vs Data Analyst: Skills, Responsibilities, Salary
Compare product analyst with data analyst roles, skills, tools, responsibilities, salaries & career growth in India to choose the right data career.
Read MoreJun 1, 2026 I 8 mins
Cold Chain Logistics in India: How It Works, Key Players, and Career Opportunities
Learn how cold chain logistics works in India, its components, technologies, top companies, salary, career opportunities, and industry trends.
Read MoreJun 6, 2026 I 11 mins
HR Analytics: Types, Benefits, Tools, and Why It Matters
Learn what HR Analytics is, its types, benefits, tools, career opportunities, salary, skills, and why HR analytics is transforming modern workforce management.
Read MoreJun 11, 2026 I 11 mins
Carbon Credits in India: Pricing, Trading, Careers, and How to Participate
Learn what carbon credits are, how carbon trading works, current pricing, opportunities, market trends, & how to participate in India's emerging carbon market.
Read MoreJun 20, 2026 I 8 mins
Revenue Analytics: Key Aspects, Software, Examples, Responsibilities & Salaries
Learn what Revenue Analytics is, how software works, real-world examples, salaries, careers, & why revenue analytics is an in-demand business skills in 2026.
Read MoreJun 28, 2026 I 11 mins
Related Articles

Predictive Analytics: Predicting Future Trends and Outcomes
Learn the importance of predictive analysis in a dynamic business environment with examples and tools for predictive analysis.
Read Blog
Data Analytics: Turning Data Into Insights and Action
Discover latest data analytics techniques & tools to extract meaningful information from complex data sets & make data-driven decisions.
Read BlogWeb Analytics: Tracking & Analyzing Website Data
In this blog find answers to what is web analytics? What is web analytics process? What is the importance of website analytics?
Read Blog
Prescriptive Analytics: Using Data to Make Better Decisions
Learn types of prescriptive techniques & examples of prescriptive analytics to make data analytics & business analysis a detailed & accurate process.
Read BlogPredictive Analytics: Predicting Future Trends and Outcomes
Learn the importance of predictive analysis in a dynamic business environment with examples and tools for predictive analysis.
Read BlogData Analytics: Turning Data Into Insights and Action
Discover latest data analytics techniques & tools to extract meaningful information from complex data sets & make data-driven decisions.
Read BlogWeb Analytics: Tracking & Analyzing Website Data
In this blog find answers to what is web analytics? What is web analytics process? What is the importance of website analytics?
Read BlogPrescriptive Analytics: Using Data to Make Better Decisions
Learn types of prescriptive techniques & examples of prescriptive analytics to make data analytics & business analysis a detailed & accurate process.
Read Blogprev
next
