

Data Mining Interview Questions Being Asked in 2026

Table of Contents:
- What is Data Mining?
- Frequently Asked Interview Questions
- Core Concept Based Questions
- Technical Interview Questions
- In-depth Questions
- Situational Questions for Freshers & Professional
Data mining remains a crucial skill in 2026, and interviews reflect the evolving landscape. Be prepared to showcase your analytical thinking, technical expertise, and real-world application of data mining concepts with these 10 frequently asked questions.
Frequently Asked Data Mining Interview Questions
- Briefly explain the different types of data mining tasks (e.g., classification, clustering, association rule mining)?
Answer: Explain the main objective of each task:
-
- Classification: Categorizing data points into predefined classes.
- Clustering: Grouping similar data points together without prior labels.
- Association rule mining: Identifying frequent patterns or relationships within data.
- Discuss the importance of data pre-processing in data mining and common techniques used.
- Answer: Highlight the impact of clean and high-quality data on mining results. Mention techniques like data cleaning, imputation, normalization, and feature scaling.
- Explain the difference between supervised and unsupervised learning algorithms and provide examples of each.
Answer: Explain that supervised learning requires labeled data:
-
- Supervised: It involves training a model on a labeled dataset where the algorithm learns from input-output pairs. The goal is to make predictions or classifications based on the learned patterns. K-Nearest Neighbors for classification, Linear Regression for prediction.
- Unsupervised: This type of learning deals with unlabeled data, and the algorithm discovers patterns and relationships without explicit guidance. Clustering and association are common tasks in unsupervised learning. K-means clustering for grouping data points, Principal Component Analysis for dimensionality reduction.
- How do you evaluate the performance of a data mining model? Mention specific metrics you consider.
- Answer: Discuss metrics like accuracy, precision, recall, F1 score for classification, and silhouette coefficient, Davies-Bouldin index for clustering. Explain the importance of choosing appropriate metrics based on the specific task.
- Describe your experience with different data mining tools and libraries (e.g., Python libraries like pandas, scikit-learn).
- Answer: Mention specific tools you’ve used and their functionalities. Showcase your knowledge of data manipulation, model building, and visualization libraries.
- How would you approach a real-world data mining problem, outlining the key steps involved?
Answer: Discuss the CRISP-DM framework (Cross-Industry Standard Process for Data Mining):
-
- Problem definition, data understanding, data preparation, modeling, evaluation, deployment, and maintenance.
- Explain the challenges you’ve faced when working with large datasets and how you tackled them.
- Answer: Discuss scaling techniques like data sampling, distributed computing frameworks (e.g., Spark), and dimensionality reduction methods.
- How do you ensure ethical considerations and responsible data mining practices?
- Answer: Discuss aspects like data privacy, bias mitigation, and explainbility of models. Mention tools or techniques you’ve used for responsible data mining.
- Discuss how data mining integrates with other fields like machine learning and artificial intelligence.
- Answer: Explain how data mining provides the foundation for ML and AI algorithms by extracting insights and preparing data for model training.
- Share a specific data mining project you worked on and the valuable insights you generated.
- Answer: Highlight a real-world project where you applied data mining techniques to solve a problem or answer a business question. Emphasize the positive outcomes and lessons learned.
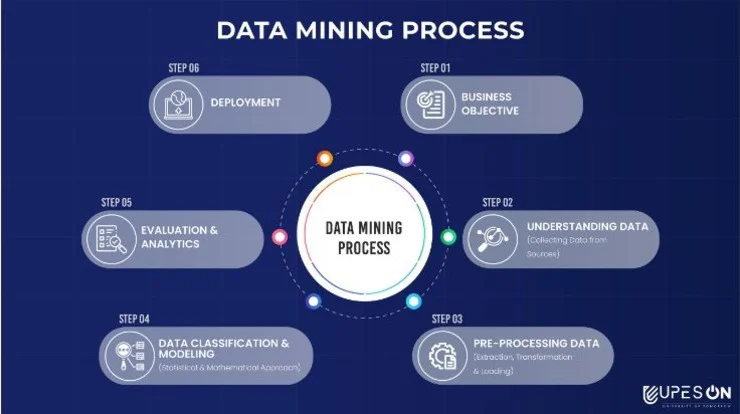
Core Concept Based Data Mining Interview Questions
1.Question: What is the fundamental difference between classification and regression in the context of data mining?
Answer:
- Classification: Involves predicting a categorical outcome or class label.
- Regression: Predicts a continuous numerical value.
2. Question: Explain the concept of dimensionality reduction and its importance in data mining.
- Answer: Dimensionality reduction involves reducing the number of input variables in a dataset. It is crucial for simplifying models, avoiding the curse of dimensionality, and improving computational efficiency.
3. Question: Can you describe the concept of ensemble learning in data mining? Provide an example.
- Answer: Ensemble learning combines multiple models to improve overall performance and robustness. An example is the Random Forest algorithm, which builds multiple decision trees and combines their predictions for more accurate and stable results.
4. Question: What is the role of a support vector machine (SVM) in data mining, and how does it work?
- Answer: SVM is a supervised learning algorithm used for classification and regression tasks. It works by finding a hyperplane that best separates data points into different classes while maximizing the margin between them.
5. Question: Explain the concept of cross-validation and why it is important in data mining.
- Answer: Cross-validation is a technique used to assess a model’s performance by splitting the dataset into multiple subsets for training and testing. It helps detect overfitting and provides a more reliable estimate of a model’s generalization performance.
6. Question: What are the key challenges in dealing with imbalanced datasets in data mining, and how can they be addressed?
- Answer: Imbalanced datasets pose challenges in classification where one class has significantly fewer instances. Techniques such as oversampling the minority class, undersampling the majority class, or using specialized algorithms like SMOTE (Synthetic Minority Over-sampling Technique) can help address these issues.
7. Question: Explain the concept of data preprocessing in the context of data mining.
- Answer: Data preprocessing involves cleaning, transforming, and organizing raw data into a format suitable for analysis. Tasks include handling missing values, normalization, and encoding categorical variables.
8. Question: What is the significance of the lift measure in association rule mining?
- Answer: Lift measures the ratio of the observed frequency of a rule to the expected frequency. It helps assess the strength of association rules, indicating how much more likely the antecedent and consequent of a rule are to occur together compared to random chance.
9. Question: Describe the difference between batch processing and real-time processing in the context of data mining.
Answer:
- Batch Processing: Involves processing data in fixed-size chunks or batches at scheduled intervals.
- Real-time Processing: Deals with analyzing and making decisions on data as it is generated in real-time, providing immediate insights.
10. Question: Explain the concept of outlier detection in data mining and provide an example of a method used for outlier detection.
- Answer: Outlier detection identifies data points that deviate significantly from the rest of the dataset. An example method is the Z-score, where outliers are identified based on their deviation from the mean in terms of standard deviations.
11. Question-How do you approach the ethical considerations of data mining, such as privacy and bias?
- Answer: Discuss anonymization techniques, differential privacy, and fair machine learning practices to mitigate privacy concerns and prevent biased models. Emphasize the importance of transparent data collection and responsible model deployment.
12. Question- Share a situation where you had to explain a complex data mining concept to non-technical stakeholders.
- Answer: Highlight your communication skills and ability to simplify technical concepts for a broader audience. Discuss the specific steps you took, the tools you used, and the positive outcomes of effective communication
13. Question Describe the K-Nearest Neighbors (KNN) algorithm and its key applications.
- Answer: Explain KNN as a classification and regression algorithm that predicts the class or value of a new data point based on its K nearest neighbors in the training data. Discuss its advantages like simplicity and non-parametric nature, and applications like text classification and recommender systems.
14. Question- Discuss the importance of data visualization in data mining and common techniques used.
- Answer: Explain how visualization helps in exploring data, identifying patterns, and communicating insights. Mention techniques like scatter plots, histograms, boxplots, and heatmaps for exploring numerical data, and network graphs for relational data.
Data Mining Interview Questions PDF
Technical Data Mining Interview Questions
- Implement the Apriori algorithm in Python for finding frequent itemsets in a transaction dataset.
- Answer: Explain the steps of generating candidate itemsets, calculating support and confidence, and pruning infrequent sets. Show code using libraries like PyCharm or Jupyter Notebook.
- Explain the process of grid search and random search for hyperparameter tuning in machine learning models.
- Answer: Compare the grid search approach of systematically evaluating all parameter combinations with the more efficient random search that samples parameter values. Mention specific libraries like GridSearchCV or RandomizedSearchCV in Python.
- Describe your experience with outlier detection techniques like isolation forest or DBSCAN.
- Answer: Explain the principle behind each technique and their suitability for different types of data and outlier patterns. Mention specific libraries like scikit-learn for implementing these algorithms.
- How would you approach feature engineering for a specific data mining task, such as text classification or image recognition?
- Answer: Discuss specific techniques like word embeddings for text or feature extraction for images. Mention tools like scikit-learn or OpenCV for feature engineering functionalities.
- Explain the concept of natural language processing (NLP) and its potential applications in data mining.
- Answer: Discuss NLP tasks like tokenization, stemming, and sentiment analysis. Mention use cases like text classification, topic modeling, and customer feedback analysis.
- How would you handle imbalanced datasets in data mining tasks, where one class has significantly fewer data points?
- Answer: Discuss techniques like oversampling the minority class, undersampling the majority class, or using SMOTE (Synthetic Minority Oversampling Technique). Mention specific libraries or tools for implementing these techniques.
- Explain the challenges and mitigation strategies for dealing with high-dimensional data in data mining.
- Answer: Discuss the curse of dimensionality problem and its impact on model performance. Mention dimensionality reduction techniques like PCA or feature selection methods.
- Describe your experience with distributed computing frameworks like Spark for handling large datasets in data mining projects.
- Answer: Explain the advantages of Spark for parallel processing and data distribution. Mention specific Spark libraries like Spark MLlib for data mining algorithms.
- How do you monitor the performance of data mining models in production environments and address potential issues?
- Answer: Discuss using metrics like accuracy, recall, and confusion matrices. Mention tools like Prometheus or Grafana for monitoring model performance and alerting for potential drifts or degradation.
- Share a technical challenge you faced during a data mining project and how you applied your skills and tools to overcome it.
- Answer: Highlight a project where you encountered a technical hurdle like imbalanced data, high dimensionality, or model performance issues. Explain your approach, tools used, and the successful outcome.
- Explain the concept of gradient boosting in machine learning and provide an example of a gradient boosting algorithm.
- Answer: Gradient boosting is an ensemble learning technique that combines the predictions of weak learners (typically decision trees) to create a strong predictive model. Examples of gradient boosting algorithms include XGBoost, LightGBM, and AdaBoost.
- What is the significance of ROC curves and AUC in evaluating classification models?
- Answer: ROC (Receiver Operating Characteristic) curves visualize the trade-off between true positive rate and false positive rate at different classification thresholds. AUC (Area Under the Curve) quantifies the overall performance of a classifier. A higher AUC indicates better discrimination between positive and negative instances.
- How does the concept of bias-variance tradeoff apply to model selection, and how can you strike a balance between bias and variance?
- Answer: The bias-variance tradeoff involves finding the right complexity for a model. A simple model may have high bias but low variance, while a complex model may have low bias but high variance. Techniques like cross-validation and regularization help strike a balance by controlling model complexity.
- Explain the purpose of the Kullback-Leibler (KL) Divergence in information theory and its application in data mining.
- Answer: KL Divergence measures the difference between two probability distributions. In data mining, it is used in tasks like clustering to assess the dissimilarity between two probability distributions, providing insights into the divergence between observed and expected outcomes
In-depth Data Mining Interview Questions
- Explain the concept of ensemble learning methods like boosting and bagging, and discuss their advantages and limitations compared to single models.
- Answer: Explain how boosting algorithms (AdaBoost) improve accuracy by iteratively focusing on misclassified examples, while bagging (Random Forests) reduces variance by averaging predictions from an ensemble of diverse models. Discuss the potential for overfitting in boosting and the computational cost of bagging.
- How would you approach dimensionality reduction for a dataset with complex non-linear relationships between features? Discuss techniques beyond traditional linear methods like PCA.
- Answer: Recommend manifold learning techniques like Isomap or Locally Linear Embedding (LLE) that can capture non-linear relationships by preserving local geometric structures in the data. Discuss their advantages over PCA in such scenarios and mention specific libraries or tools for implementing them.
- Discuss the potential ethical considerations and biases that can arise in data mining projects, and suggest strategies for mitigating them.
- Answer: Explain how biased data or algorithms can lead to unfair or discriminatory outcomes. Discuss techniques like data pre-processing to address bias, explainable AI approaches to ensure transparency, and fairness metrics like equal opportunity or calibration fairness to evaluate model bias.
- Imagine you’re presented with a streaming dataset, where data arrives continuously. How would you adapt your data mining approach to handle this scenario effectively?
- Answer: Discuss online learning algorithms like gradient descent or adaptive boosting that can continuously update models with new data. Mention streaming data processing frameworks like Apache Spark or Kafka for handling real-time data ingestion and analysis.
- Share a complex data mining project you tackled where you had to go beyond standard techniques to achieve successful results. Explain your approach and the innovative solutions you implemented.
- Answer: Focus on a project that challenged your skills and required deep theoretical understanding or creative problem-solving. Explain the specific challenges you faced, the unique techniques you employed (e.g., custom feature engineering, novel algorithms), and the positive outcomes achieved.
Situation Based Interview Questions
Apply theoretical knowledge and technical skills in real-world scenarios with these 5 situational questions:
- You’re tasked with predicting churn rate for a mobile app using user activity data. How would you approach this problem from a data mining perspective?
Answer:
- Highlight initial data exploration techniques like user segmentation, analyzing app usage patterns, and identifying correlation with churn events.
- Discuss implementing supervised learning algorithms like logistic regression or random forests for churn prediction.
- Mention feature engineering techniques like creating user engagement metrics or session frequency features.
- Emphasize the importance of model evaluation and iteratively improving the model performance using techniques like cross-validation.
- A retail company seeks to identify customer segments based on their purchase history. What data mining techniques and tools would you recommend?
Answer:
- Suggest applying unsupervised learning algorithms like K-means clustering or hierarchical clustering to group customers based on similar purchase patterns.
- Mention analyzing purchasing frequency, product categories, and average order value as potential features for clustering.
- Discuss using visualization tools like scatter plots or heatmaps to explore the clusters and identify key characteristics of each segment.
- Recommend utilizing tools like Python libraries (Pandas, scikit-learn) or data mining platforms (RapidMiner, KNIME) for these tasks.
- An e-commerce website experiences a sudden drop in online sales. How would you use data mining to diagnose the issue and propose potential solutions?
Answer:
- Suggest analyzing website traffic logs, user browsing behavior, and product abandonment data to identify potential bottlenecks in the customer journey.
- Discuss utilizing anomaly detection techniques to pinpoint specific timeframes or product categories with significant sales decline.
- Recommend analyzing user reviews and feedback to understand potential customer perception issues or website usability problems.
- Propose solutions based on the identified root cause, such as website optimization, targeted promotions, or product recommendations.
- You’re given access to a large social media dataset. How would you leverage data mining to extract insights and inform marketing strategies?
Answer:
- Discuss applying sentiment analysis techniques to understand user opinions and brand perception on social media.
- Suggest identifying trending topics and influencer networks to guide content creation and targeted marketing campaigns.
- Recommend performing social network analysis to discover communities and relationships between users for improved user segmentation and engagement strategies.
- Emphasize the importance of ethical considerations like data privacy and responsible communication when utilizing social media data.
- You’re tasked with implementing a data mining project for a client with limited technical knowledge. How would you explain your approach and communicate the insights in a clear and concise way?
Answer:
- Use simple language and analogies to explain the data mining concepts and methodologies used.
- Focus on translating the results into actionable insights that address the client’s specific business objectives.
- Use visualization tools like charts and graphs to present data and findings in a clear and understandable way.
- Encourage open communication and answer questions to ensure the client understands the data’s value and its potential impact.
Remember, these are just starting points. Tailor your answers to showcase your specific expertise, problem-solving approach, and ability to adapt to real-world scenarios. By demonstrating your critical thinking, communication, and collaborative skills, you’ll impress the interviewers and showcase your ability to thrive in a data-driven environment.
UPES Online Admission Enquiry
Recommended Courses



Latest Blogs

Online MBA Exam Patterns: What to Expect & How to Prepare
Know the online MBA exam pattern in India. Assessment weightage, proctored exams, security & practical preparation strategies for online learners.
Read MoreJan 20, 2026 I 7 mins
General MBA vs Specialized MBA: How to Choose Your Path in 2026?
General MBA vs specialized MBA compared on metrics like scope, ROI, salary & career growth in India. Understand the path & choose wisely.
Read MoreMay 3, 2026 I 8 mins
Product Analyst vs Data Analyst: Skills, Responsibilities, Salary
Compare product analyst with data analyst roles, skills, tools, responsibilities, salaries & career growth in India to choose the right data career.
Read MoreJun 1, 2026 I 8 mins
Cold Chain Logistics in India: How It Works, Key Players, and Career Opportunities
Learn how cold chain logistics works in India, its components, technologies, top companies, salary, career opportunities, and industry trends.
Read MoreJun 6, 2026 I 11 mins
HR Analytics: Types, Benefits, Tools, and Why It Matters
Learn what HR Analytics is, its types, benefits, tools, career opportunities, salary, skills, and why HR analytics is transforming modern workforce management.
Read MoreJun 11, 2026 I 11 mins
Carbon Credits in India: Pricing, Trading, Careers, and How to Participate
Learn what carbon credits are, how carbon trading works, current pricing, opportunities, market trends, & how to participate in India's emerging carbon market.
Read MoreJun 20, 2026 I 8 mins
Revenue Analytics: Key Aspects, Software, Examples, Responsibilities & Salaries
Learn what Revenue Analytics is, how software works, real-world examples, salaries, careers, & why revenue analytics is an in-demand business skills in 2026.
Read MoreJun 28, 2026 I 11 mins
Related Articles

Ace Your Data Governance Interview with these 55 Question Types
Master 55 data governance interview Questions, from data lineage puzzles to AI challenges. Sharpen your skills & land your dream data role.
Read BlogAce Your Data Governance Interview with these 55 Question Types
Master 55 data governance interview Questions, from data lineage puzzles to AI challenges. Sharpen your skills & land your dream data role.
Read BlogAce Your Data Governance Interview with these 55 Question Types
Master 55 data governance interview Questions, from data lineage puzzles to AI challenges. Sharpen your skills & land your dream data role.
Read BlogAce Your Data Governance Interview with these 55 Question Types
Master 55 data governance interview Questions, from data lineage puzzles to AI challenges. Sharpen your skills & land your dream data role.
Read BlogAce Your Data Governance Interview with these 55 Question Types
Master 55 data governance interview Questions, from data lineage puzzles to AI challenges. Sharpen your skills & land your dream data role.
Read Blog